
시작하기 앞서서 같은 의미의 다양한 용어를 정리해보자
- feature = variable, column in a table, dimension
- observation, sample = rows, records
- entity = Pandas Data Frame, RDB table
- entity set = set of entities, RDB tables
- shared variable = RDB foreign key
- transformation = deriving a new feature from existing features within an entity
- aggregation = merging different entities, or calculating statistics on a group of rows in an entity and merging the result as a feature of another entity
Feature Engineering은 3가지로 구분할 수 있다.
- Feature Creation : 원본 데이터로부터 모델 학습에 도움이 되는 새로운 특성을 만드는 과정
- Feature selection : 기존 특성 중에서 모델 성능에 도움이 되는 유의미한 특성만 선택
- Feature Reduction : 연관성을 이용해 feature의 수를 줄이는 방식
Feature Creation
Deriving Features from Existing Features
1. 존재하는 Feature로부터 새로운 feature 생성 (같은 테이블 내)
- 기존 수치형 데이터를 범주형으로 변환(binning, categorizing)

- 카테고리를 상위 그룹으로 묶는 방식 (categorical grouping)

- 하나의 특성을 여러 특성으로 split


- 수치형 데이터를 함수로 변환하여 스케일 조정 ex) 로그 변환
2. merging, aggregating을 통해 새로운 feature 생성 (다른 테이블간)
머신 러닝에서는 테이블을 하나만 쓰기 때문에 여러 테이블을 join을 통해 합쳐야 한다.
import pandas as pd
import featuretools as ft
# clients 데이터
clients = pd.DataFrame({
'client_id': [25707, 39384, 49624, 29841, 39505, 44601],
'joined': ['2002-04-16', '2007-11-14', '2013-03-11', '2001-11-06', '2006-10-06', '1999-05-29'],
'income': [172677, 104564, 122607, 43851, 211422, 299300],
'credit_score': [527, 770, 585, 562, 621, 800]
})
clients['joined'] = pd.to_datetime(clients['joined'].str.strip(), errors='coerce')
# loans 데이터
loans = pd.DataFrame({
'loan_id': [10438, 10579, 10578, 10157, 10407, 10362, 10868],
'client_id': [25707, 39384, 49624, 29841, 39505, 44601, 39384],
'loan_amount': [9942, 13131, 2572, 10537, 6484, 4475, 1770],
'joined': pd.to_datetime(['2009-03-26', '2012-08-12', '2004-05-04', '2010-08-04', '2011-02-14', '2005-07-29', '2013-08-03'])
})
# payments 데이터
payments = pd.DataFrame({
'payment_id': [1, 2, 3, 4, 5, 6, 7],
'loan_id': [10438, 10579, 10578, 10157, 10407, 10362, 10868],
'amount': [100, 200, 300, 400, 500, 600, 700]
})
# EntitySet 생성
es = ft.EntitySet(id='loan_data')
# 데이터프레임 등록
es = es.add_dataframe(dataframe_name='clients', dataframe=clients, index='client_id', time_index='joined')
es = es.add_dataframe(dataframe_name='loans', dataframe=loans, index='loan_id', time_index='joined')
es = es.add_dataframe(dataframe_name='payments', dataframe=payments, index='payment_id')
# 관계 정의
es = es.add_relationship(
parent_dataframe_name='clients',
parent_column_name='client_id',
child_dataframe_name='loans',
child_column_name='client_id'
)
es = es.add_relationship(
parent_dataframe_name='loans',
parent_column_name='loan_id',
child_dataframe_name='payments',
child_column_name='loan_id'
)
# 확인 출력
print("✅ EntitySet 생성 성공:")
# loans를 client_id 기준으로 clients에 병합
stats = loans.groupby('client_id')['loan_amount'].agg(['sum','mean', 'max', 'min'])
stats.columns = ['total_loan_amount','mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
stats = clients.merge(stats, left_on='client_id', right_index=True, how='left')
print(stats.head(10))
# payments와 loans를 loan_id,client_id 기준으로 병합
loan_payment_merged = payments.merge(loans[['loan_id', 'client_id']], on='loan_id')
# client_id 기준으로 집계
payment_stats = loan_payment_merged.groupby('client_id')['amount'].sum().reset_index()
payment_stats.columns = ['client_id', 'total_payment_amount']
# 기존 stats에 병합
stats = stats.merge(payment_stats, on='client_id', how='left')
print(stats.head(10))
Converting Values to New Features
값을 feature로 변환하는 대표적인 방법은 3가지가 있다.
- 범주형 → 숫자형 (예: One-Hot Encoding)
- 텍스트 → 벡터 (예: Word Embedding)
- 이미지 → 픽셀 값 (각 픽셀을 feature로 사용)
1. 범주형 데이터를 Feature로 변환
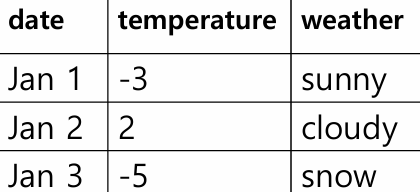
위 그림 처럼 weather라는 컬럼에 sunny, cloudy 등이 있다면 각 값이 새로운 컬럼으로 나뉜다.

이러한 방식을 One-Hot Encoding이라 한다.
장점: 모델이 이해할 수 있는 숫자로 변환됨
단점: 컬럼 수 증가, 희소 행렬(Sparse Matrix) -> 대부분이 0의 값을 가지게 된다.
2. 단어(corpus)를 벡터로 변환
- One-Hot Vector: 단어를 1개의 1과 나머지 0으로 구성된 긴 벡터로 표현 (예: 10,000 차원)
- Word Embedding: 단어를 의미적으로 압축된 벡터로 표현 (Word2Vec, GloVe 등)
3. 이미지 데이터를 Feature로 변환
픽셀 → Feature
- 예: 이미지가 100x100 픽셀이라면 → 10,000개의 숫자 feature
- 각 픽셀은 정수값 (0~255) 또는 이진값 (0/1)로 표현
Feature Selection
데이터의 feature 수가 너무 많아지면 다양한 문제들이 생긴다.
- 계산량 폭증: 수백~수천 개의 피처는 학습 시간 및 메모리 사용량 폭발
- 시각화 불가: 2D/3D로 시각화할 수 없어 이해와 해석이 어려움
- 모델 과적합: 너무 많은 피처 → 모델이 데이터를 지나치게 암기(overfit)
- 데이터 희소화(sparse): 고차원일수록 대부분의 값이 0 → 통계적으로 무의미
- 거리 기반 알고리즘 무력화: 고차원에서는 거리(distance) 계산의 의미가 없어짐
(→ KNN, 군집화 등에서 성능 저하)
그렇기 떄문에 의미 있는 feature만을 selection하여 성능 향상 + 과적합 방지 + 계산 자원 절약을 한다.
feature selection은 어떤 조합을 시도할 것인지 (Search Technique) , 어떤 피처 조합이 더 좋은지 어떻게 평가 할 것인지 (Evaluation Measure)에 초점을 둔다.
feature selection의 방법에는 Filter , Wrapper, Embedded 가 있다.
1. Filter Method
- 데이터 특성만 보고 미리 걸러냄
- 머신러닝 모델과 완전히 분리되어 있음
- 빠르고 간단하지만, 피처 간 상호작용을 반영하지 못함
- ex) 카이제곱 검정 (chi²), ANOVA, Pearson 상관계수, SelectKBest (Scikit-learn)
Wrapper Method
- 직접 모델을 학습시켜서 피처 조합의 성능을 평가
- 모든 조합을 실험 → 시간이 오래 걸림
- 정확도는 높을 수 있음 (하지만 과적합 위험)
- ex) RFE (Recursive Feature Elimination) , Sequential Feature Selector (SFS)
Embedded Method
- 모델이 학습하면서 동시에 feature 선택까지 수행
- 가장 효율적인 방법 중 하나
- 모델에 따라 자동으로 피처 중요도를 계산
- ex) L1 정규화 (Lasso Regression): 계수를 0으로 만들어 중요하지 않은 피처 제거, Tree-based models (RandomForest, XGBoost 등): feature importance 속성 내장
Python에서 자주 쓰는 Feature Selection 기법은 다음과 같다.

실습
# Scikit-learn에서 제공하는 캘리포니아 주택 가격 데이터셋 불러오기
from sklearn.datasets import fetch_california_housing
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.ensemble import ExtraTreesRegressor
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 1. 데이터 불러오기
california = fetch_california_housing(as_frame=True)
df=pd.DataFrame(california.data, columns=california.feature_names)
# 2. X: 피처 / y: 타겟 분리
X = california.data
y = california.target
# 3. SelectKBest 적용
selector = SelectKBest(score_func=f_regression, k='all')
X_new = selector.fit_transform(X, y)
# 4. 선택된 피처 이름 확인
selected_features = X.columns[selector.get_support()]
selected_scores=selector.scores_[selector.get_support()]
# 5. 결과 시각화
feature_scores = pd.DataFrame({
'Feature': selected_features,
'Score': selected_scores
}).sort_values(by='Score', ascending=False)
print(feature_scores)
# 6. 트리 기반 중요도 평가
model=ExtraTreesRegressor()
model.fit(X,y)
importances =model.feature_importances_
# 7. 중요도 높은 상위 5개 피처 plot 시각화
importances=pd.Series(model.feature_importances_,index=X.columns)
importances.nlargest(5).plot(kind='barh')
# 8. 상관관계 시각화
corr=df.corr()
plt.figure(figsize=(10,10))
sns.heatmap(corr,annot=True,cmap="RdYlGn")
plt.title('Feature Correlation Matrix')
plt.show()
Feature reduction
필요한 feature만 골라내는 Feature selection과는 다르게 Feature Reduction은 feature의 관계를 이용하여 합쳐서 줄이는 방식이다.
Feature reduction의 몇 가지 방식
- Principal Component Analysis (PCA) : 데이터를 선형 변환하여 가장 많은 정보량을 가진 주성분 축으로 표현
- Singular Value Decomposition (SVD) : 행렬 분해를 이용한 차원 축소 방법
- Linear Discriminant Analysis (LDA) : 클래스 간 분산은 최대화, 클래스 내 분산은 최소화하는 방향으로 축 선택
- Autoencoder(신경망 기반) : 입력을 압축했다가 다시 복원하는 구조로 특징을 추출하는 비지도 학습 방식
- Self-Organizing Map(SOM): 비지도 학습 방식의 신경망으로, 고차원 데이터를 2D 형태로 군집화
Principal Component Analysis (PCA)
주성분(Principal Component, PC)은 원래 데이터에서 가장 넓게 퍼진 방향으로의 직선 축을 의미한다.
분산 (Variance)은 데이터가 퍼져 있는 정도를 의미한다. 분산이 클 수록 더 많은 정보를 담고있다. 여기서 정보가 많다는 뜻은 데이터의 구분이 쉽다는 의미이다.
고유벡터(Eigenvector)는 주성분의 방향을 의미한다.
고유값(Eigenvalue)은 각 고유벡터에 대응하는 분산의 크기이다.
PCA에서 생성되는 각각의 주성분(Principal Component)은 반드시 서로 직교(orthogonal)한다.
또한, 주성분을 기준으로 데이터를 투영시켜 만들어진 새로운 특성은 원래 특성들의 선형 결합으로 만들어진다.

분산이 가장 큰 (데이터의 구분이 쉬운) 주성분(ev1)을 기준으로 각 데이터를 투영시켜서 새로운 특성을 만든다.
ex) PCA 계산 결과 주성분 방향이 아래와 같이 나왔다면

주성분 PC1= 0.8x + 0.6y
주성분은 n차원 공간에서는 최대n개가 존재할 수 있다. (n개 이면 차원 축소는 안 된 상태)
보통 분산이 큰 상위 k개의 주성분만 선택해서 k<n인 상태로 차원 축소를 한다.
MNIST(Mixed National Institute of Standards and Technology) 데이터셋은 0부터9까지의 손글씨 숫자 이미지로 구성된 머신러닝용 대표 이미지 데이터셋이다.
