
Single Cycle 개념
Single-Cycle 설계란 모든 명령이 한 번의 클록 안에 실행되는것을 의미다.
구조가 단순하지만 비효율적인데 대표적인 문제점은 다음과 같다.
- 클록 주기가 가장 느린 명령(load) 에 맞춰야 함
→ 모든 명령이 느려짐 - 메모리 분리 필요 : 명령어 메모리와 데이터 메모리를 따로 둬야 함
- 여러 ALU/Adder 필요 : 주소 계산, PC 증가, 연산을 동시에 해야 하므로
- 성능 저하 : 실제 평균 실행시간보다 24% 느림 (예: gcc 기준) , 부동소수점 연산이 있으면 더 악화됨

CPU의 성능은 위와 같이 계산할 수 있는데 Single-cycle에서는 CPI가 1로 동일하며 결국 CCT가 길수록 느려진다. 이를 해결하기 위해서 파이프라인이라는 기술을 사용한다.
Pipelining
pipelining은 여러 명령어를 겹쳐 실행해 CPU 성능을 높이는 구조적 기술이며, 오늘날 프로세서의 기본 설계 방식이다.
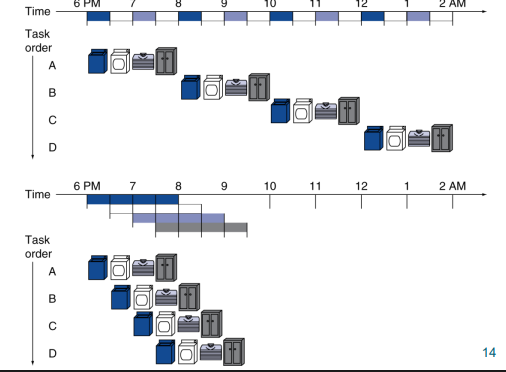
빨래를 예시로 들어보면 아래쪽 그림은 세탁, 건조, 개기, 정리의 4가지 단계를 겹쳐서 실행함으로써 8시간 걸리는 작업을 3.5시간만에 끝냈다.
만약 4개가 아닌 n개의 빨래를 pipelining 형식으로 설계를 한다면
2n / 0.5n =4
즉, 단계의 수 만큼 효율을 얻을 수 있다. 하지만 실제로는 그 정도의 효율은 나오지 않는다. 그 이유는 추후에 알아보겠다.
LEGv8의 pipelining
single cycle 기준에서 LEGv8의 파이프라인은 5단계로 나뉜다.
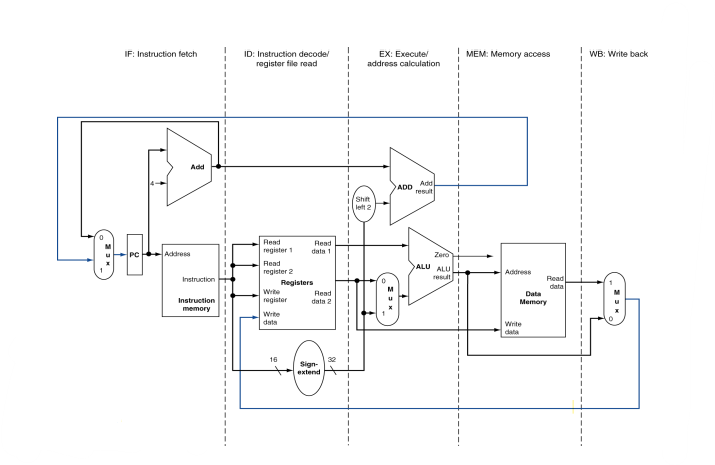
| 단계 | 이름 | 주요 기능 |
| 1. IF (Instruction Fetch) | 명령어를 메모리에서 읽기 | Program Counter(PC)를 이용해 Instruction Memory에서 명령어를 가져옴. |
| 2. ID (Instruction Decode & Register Read) | 명령어 해석 및 레지스터 읽기 | 명령어의 필드(opcode, register 등)를 해석하고, 필요한 레지스터 값을 읽음. |
| 3. EX (Execute / Address Calculation) | 연산 수행 또는 주소 계산 | ALU를 이용해 산술·논리 연산 또는 메모리 접근 주소 계산 수행. |
| 4. MEM (Memory Access) | 데이터 메모리 접근 | Load는 메모리에서 데이터를 읽고, Store는 데이터를 메모리에 씀. |
| 5. WB (Write Back) | 결과를 레지스터에 저장 | ALU나 메모리 결과를 레지스터 파일에 다시 기록. |
각 단계 중 Register Read , Write는 100ps , 나머지는 200ps 만큼의 시간이 든다고 가정 한 후 각 Instruction의 시간을 구해보면 다음과 같다.

LDUR로 예를 들면 파이프라인 단계가 5개이므로, 이론적으로는 single-cycle과 비교하여 speed up이 5배가 되어야 한다.
이상적인 상황에서는 800ps / 5 = 160ps로 모든 단계가 160ps가 걸릴경우 5배가 되지만 실제로 각 단계별로 걸리는 시간이 다르므로 클록은 가장 긴 단계인 200ps 를 기준으로 맞추게 된다. 이 불균형 때문에 실제 속도향상은 약 4배 수준으로 떨어지게 된다.
또한, 오버헤드나 Hazard로 인해 성능이 더 떨어지는데 이에 대해 살펴보자
pipeline Overhead
오버헤드는 파이프라인 구조를 유지하기 위해 추가로 필요한 하드웨어 처리 시간과 제어 비용을 의미한다.
발생 원인 :
| 구성요소 | 역할 | 부작용 |
| Pipeline Register | 각 단계의 출력 값을 다음 단계로 전달할 때 저장 | 각 레지스터에 클록 동기화 지연(몇 ps) 발생 |
| Control Logic | 단계별 제어 신호를 생성하고 유지 | 회로 복잡도 증가 → 타이밍 제약 강화 |
| Hazard Detection / Forwarding Logic | 데이터 의존성 검출 및 우회 경로 관리 | 추가 하드웨어 연산 지연 발생 |
Hazard란 파이프라인의 흐름이 멈추거나 잘못된 명령어가 실행되는 상황으로 LEGv8에서는 총 3가지 Hazard가 존재한다.
- Structure Hazard
- Data hazard
- Control hazard
Structure Hazard
Structure Hazard란 파이프라인의 여러 단계가 동시에 같은 하드웨어 자원을 사용하려 할 때 발생하는 충돌이다.
LEGv8는 명령어 메모리와 데이터 메모리가 같이 존재하는 단일 메모리 구조이다.
LDUR X1, [X2, #8] ; 메모리 접근 (데이터 읽기)
ADD X3, X1, X4 ; 다음 명령어 읽기 (명령어 접근)
| 사이클 | IF 단계 | MEM 단계 | 충돌 여부 |
| ① | LDUR 명령어 읽기 | – | 정상 |
| ② | ADD 명령어 읽기 | LDUR이 데이터 메모리 접근 | ⚠️ 둘 다 같은 메모리 접근 → Hazard! |
위의 예시 중 2번 사이클에서 같은 메모리에 다른 작업이 접근하게 되면 한 쪽은 대기(stall)을 해야 하는데 이를 bubble이 발생했다고 한다.
방법 ① — 메모리 분리 (Harvard Architecture)
- Instruction Memory 와 Data Memory 를 물리적으로 분리.
- 즉, 명령어 전용 메모리와 데이터 전용 메모리를 각각 둠.
- 파이프라인의 IF와 MEM 단계가 동시에 메모리 접근 가능 → hazard 해결
방법 ② — 캐시 분리
- 실제 하드웨어에서는 Instruction Cache (I-Cache) 와 Data Cache (D-Cache) 를 분리함.
- 명령어 캐시는 읽기 전용, 데이터 캐시는 읽기·쓰기 모두 가능.
- 물리적 메모리는 공유하더라도, 동시에 접근 가능한 캐시 구조로 hazard 방지.
Data Hazard
Data Hazard란 어떤 명령어가 이전 명령어의 결과 값을 필요로 하지만 그 값이 아직 파이프라인 내에서 계산 중이라 레지스터에 기록되지 않은 상태일 떄 발생하는 문제이다.
즉, 필요한 데이터가 아직 나오지 않았는데 다음 명령어가 먼저 실행되는 상황으로 파이프라인을 멈추거나(stall) 우회(forwarding)해야한다.
ADD X19, X0, X1 ; X19 ← X0 + X1
SUB X2, X19, X3 ; X2 ← X19 - X3
ADD의 명령어 결과 (x19) 는 WB 단계에서야 실제로 레지스터에 기록됨
SUB 명령어는 ID 단계에서 X19를 읽으려함
-> 따라서 아직 ADD의 결과가 존재하지 않음 : Data Hazard 발생
방법 ① — Forwarding (Bypassing)
값을 “레지스터에 쓰기 전에” 바로 다음 명령어로 전달해서
기다리지 않고 바로 사용하는 방법

ADD가 EX의 단계에서 결과를 내는 순간, 결과를 바로 SUB의 EX단계로 전달한다.
방법 ② — Stall (Bubble 삽입)
Forwarding으로도 해결할 수 없는 Load-use hazard에서 사용.
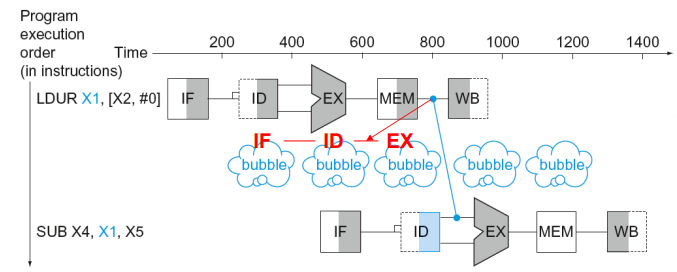
LDUR은 데이터 메모리 접근이 필요한 명령어로 실제 데이터는 MEM 단계가 끝나야 도착한다.
따라서 ADD 명령이 EX 단계에 들어가려 하면 아직 데이터가 없으므로 1사이클을 정지(stall) 시켜 버블을 넣는다.
이러한 stall을 피하기 위해 의도적으로 코드를 변경하는 code Scheduling을 사용한다.

왼쪽 그림에서는 ADD 명령어들이 직전 LDUR 결과값을 바로 사용하려 해서 stall이 2번 발생하지만 오른쪽처럼 코드를 변경하게 되면 stall이 없어지게 된다.
Control Hazard
Control Hazard는 분기(branch) 혹은 점프(jump) 명령어 때문에 다음에 어떤 명령어를 실행해야 할 지 확정되지 않아 파이프라인이 멈추는 현상이다.
IF → ID → EX → MEM → WB
CBZ X1, L1 ; X1이 0이면 L1로 점프
ADD X2, X3, X4 ; (분기 안 할 경우 실행)
SUB X5, X6, X7
...
L1: MUL X8, X9, X10
IF 단계에서는 PC를 이용해 다음 명령어를 미리 읽는데 분기 명령어는 EX 단계가 되어야 결정이된다.
위의 예시에서 x1=0일 때, L1으로 점프해야 하는데 다음 명령어를 미리 읽어서 ADD 와 SUB 를 미리 불러오면 잘못된 명령어 fetch가 발생하고 이를 Control Hazard라고 한다.
방법 ① — Stall until branch resolved
분기 결과가 확정될 때까지 파이프라인을 멈춤.
- 분기마다 2~3 사이클 stall 발생 → 성능 급감.

➡ 간단하지만 비효율적 → 현대 CPU에서는 거의 사용하지 않음.
방법 ② — Predict Not Taken (Static branch Prediction)
분기가 안 걸린다(not taken) 고 가정하고 그냥 다음 명령어를 실행함.
- 만약 실제로 “분기 안 함” → OK (성공)
- 실제로 “분기 함” → 틀렸으므로 잘못 fetch한 명령어들을 flush(무효화) 해야 함.

if 문처럼 forward branch가 많을 때 유용
방법 ③ — Predict Taken(static branch prediction)
항상 “분기한다(taken)”고 예측하고,
분기 대상 주소(branch target)를 미리 fetch.
- 루프(loop) 문처럼 backward branch가 많을 때 유용.
- forward branch에서는 예측 실패 가능성 높음.
방법 ④ — Dynamic Branch Prediction (적응형 예측)
하드웨어가 이전 분기 이력(Branch History) 을 저장해,
최근 패턴을 기반으로 다음 분기를 예측.
- 과거에 CBZ X1, L1이 5번 중 4번 “taken”이었다면
다음에도 taken으로 예측. - Branch Prediction Buffer (BPB) or Branch History Table (BHT) 사용.
- 성능 손실을 거의 없앨 수 있음.
