
Floating Point (부동소수점) 기본
- 정수가 아닌 매우 작거나 큰 수 표현용 형식.
- 과학적 표기법 과 유사 (예: –2.34 × 10⁵⁶).
- 이진 정규화 표기: ±1.xxxxxx₂ × 2ʸʸʸʸ
- 항상 1로 시작하는 정규화된 형태 (normalized).
- C 언어의 float (32비트) / double (64비트)이 이 형식 사용.
🔸 10진에서는 정규화 수가 1~9로 시작하지만,
2진에서는 0과 1뿐이므로 항상 fraction 앞에 1이 온다.
IEEE Floating-Point Standard
- IEEE 754 (1985) : 전기전자기술자협회(IEEE) 정의.
- 과거 서로 다른 표현 방식 → 호환성 문제 → 통일된 표준 필요.
- 현재 모든 과학/공학 계산에 사실상 전 세계적 표준.
- 두 형식 제공:
- Single Precision (32 bit)
- Double Precision (64 bit)
IEEE 754 Encoding
IEEE Floating-Point Format 세부 구조

| 필드 | 의미 | 비트수(single/double) |
| S | 부호 (0 양수, 1 음수) | 1 |
| Exponent | 지수 = actual exponent + bias | 8 / 11 |
| Fraction | 유효숫자 부분 (significand) | 23 / 52 |
- Significand(=Fraction + 숨은 비트 1) 은 항상 1.0 ≤ |값| < 2.0 의 정규화 형태.
- 지수는 음수를 표현하기 위해 bias 사용.
- Single : Bias = 127
- Double : Bias = 1023
Single Precision 범위
- Exponent = 8비트, Fraction = 23비트.
- 00000000 과 11111111 은 특수 값 예약.
| 항목 | Exponent | 실제 지수 | Approx 값 |
| 최소 정규화 값 | 00000001 | 1 – 127 = –126 | ±1.0 × 2⁻¹²⁶ ≈ ±1.2×10⁻³⁸ |
| 최대 정규화 값 | 11111110 | 254 – 127 = +127 | ±2.0 × 2¹²⁷ ≈ ±3.4×10³⁸ |
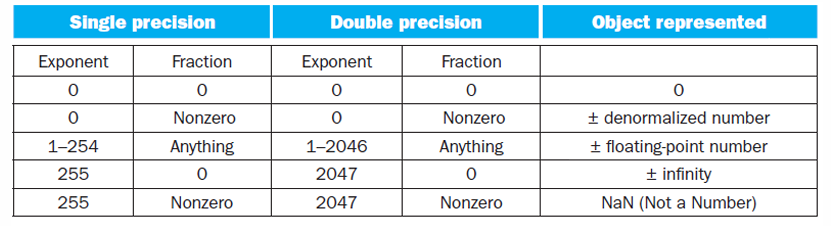
- Exponent = 0 또는 255는 특수 케이스(0, NaN, ∞ 등).
Underflow vs Overflow
- Overflow: 결과가 표현 가능한 최대값 초과.
- Underflow: 너무 작은 값이라 표현 불가.
- 지수가 너무 음수가 되어 필드 범위 벗어남.
- → 해결책: 지수 필드 비트를 늘리면 범위 확장.
Double Precision 범위
| 항목 | Exponent | 실제 지수 | Approx 값 |
| 최소 정규화 값 | 00000000001 | 1 – 1023 = –1022 | ±1.0 × 2⁻¹⁰²² ≈ ±2.2×10⁻³⁰⁸ |
| 최대 정규화 값 | 11111111110 | 2046 – 1023 = +1023 | ±2.0 × 2¹⁰²³ ≈ ±1.8×10³⁰⁸ |
- Exponent = 0 또는 2047은 특수 값 (0, NaN, ∞).
Floating-Point Precision (정밀도)
- Relative precision = fraction 비트 수가 결정.
| 형식 | Fraction 비트 | 정밀도 (≈2⁻ⁿ) | 10진 자리 |
| Single | 23 | ≈ 2⁻²³ | ≈ 6 자리 |
| Double | 52 | ≈ 2⁻⁵² | ≈ 16 자리 |
즉, float는 약 6자리, double은 약 16자리의 유효 10진 정밀도를 가짐.
Fraction은 실제 값의 소수 부분을 나타낸다
Significand는 항상 1 + Fraction 형태이며,
이 부분이 수의 정밀도(precision) 를 결정한다.
- n = fraction 비트 수
- float: n = 23
- double: n = 52
- 실제 유효비트: n + 1 (숨은 1 포함)
인접한 두 부동소수점 수의 차이
정규화된 수의 인접한 두 값은 fraction이 1 LSB(=2⁻ⁿ)만큼 다르다

따라서 두 수의 차이:

여기서 E, n의 의미
| 기호 | 의미 | 역할 |
| E | 실제 지수 (Exponent - Bias) | 수의 전체 크기(스케일)를 결정 |
| n | Fraction 비트 수 | 정밀도(간격의 세밀함)를 결정 |
| Δx = 2^{E−n} | 인접한 두 수의 거리 | E가 크면 간격 커지고, n이 많으면 간격 작아짐 |
즉,
- E ↑ → 값이 커질수록 표현 간격도 커짐 → 정밀도↓
- n ↑ → fraction 비트 많을수록 간격 줄어듦 → 정밀도↑
상대 오차 (Relative Error)
정규화된 수의 상대 오차는 다음과 같다:

즉,

따라서 상대 오차 ≈ 2⁻ⁿ
이게 바로 “부동소수점 정밀도(precision)”의 수학적 정의이다.
float vs double 비교
| 형식 | n(fraction 비트) | 상대 오차 ≈ 2⁻ⁿ | 실제 값 | 10진 정밀도 (≈ n × log₁₀2) |
| float (32bit) | 23 | 1.19×10⁻⁷ | 1 + 1.1920929×10⁻⁷ | ≈ 7.22자리 (보장 6자리) |
| double (64bit) | 52 | 2.22×10⁻¹⁶ | 1 + 2.2204460×10⁻¹⁶ | ≈ 15.95자리 (보장 15자리) |
즉,
- float는 약 10⁻⁷ 수준의 상대 오차
- double은 약 10⁻¹⁶ 수준의 상대 오차
왜 “6자리 / 16자리”라고 하는가?
이론적으로는 log₁₀(2)×(n+1)자리 정밀도지만,
모든 수를 정확히 10진으로 변환할 수 없기 때문에
항상 보장되는 유효 자릿수는 약간 낮게 잡는다.
| float | 약 7.22자리 | 약 6자리 |
| double | 약 15.95자리 | 약 15자리 |
즉,
“float는 6자리, double은 16자리 정밀도”란
항상 신뢰할 수 있는 10진 유효자릿수(significant digits) 를 뜻합니다.
Precision vs Accuracy (정밀도 vs 정확도)
| Precision | 정밀도 | 인접 수 간격이 얼마나 세밀한가 (비트 수로 결정) | |
| Accuracy | 정확도 | 계산 결과가 실제 참값에 얼마나 가까운가 |
IEEE 754에서 “single-precision”, “double-precision”은
모두 정밀도(Precision) 를 뜻함.
정확도(Accuracy)와는 별개 개념.
example - 10진수 실수 -> 부동소수점 2진 표현

부동 소수점 2진 표현 -> 10진수 실수

Denormal Numbers
Denormal Numbers
→ exponent = 0일 때 hidden bit이 0으로 바뀌며
실제 지수는 1−Bias로 고정되어
정규화 수보다 더 작은 수를 표현하고,
underflow를 부드럽게 처리한다.
Infinities & NaN
→ exponent = all 1s인 경우
fraction이 0이면 ±∞,
fraction이 0이 아니면 NaN (정의되지 않은 결과)로 처리한다
Floating Point Addition
기본적으로 Floating point의 덧셈 절차는 다음과 같다
| ① 정렬 (Align) | 지수가 작은 수의 가수(mantissa) 를 오른쪽으로 shift → 두 수의 지수를 같게 맞춤 | |
| ② 덧셈/뺄셈 (Add/Sub) | 부호가 같으면 덧셈, 다르면 뺄셈 수행 | |
| ③ 정규화 (Normalize) | 결과가 1.xxxx 형태가 되도록 조정 → 필요 시 지수 ±1 | |
| ④ 반올림 (Round) | 23비트(또는 52비트)까지만 유지 → “Round to nearest even” 규칙 사용 | |
| ⑤ 예외 처리 (Exception) | Overflow → ∞, Underflow → 0 또는 Denormal 처리 |
먼저, 10진수의 예시이다.

다음 2진수의 예시이다.

Floating Point Multiplication , division
다음은 부동소수점의 곱셈이다.
단계 이름 핵심 내용
| ① 부호 결정 (Sign) | (S = S_1 ⊕ S_2) (XOR 연산) | |
| ② 지수 계산 (Exponent) | (E = (E_1 + E_2) - Bias) | |
| ③ 가수 곱셈 (Mantissa) | ((1 + F_1) × (1 + F_2)) — 결과는 약 2~4비트 늘어남 | |
| ④ 정규화 (Normalization) | 결과가 1.x 형태가 아니면 이동 후 지수 ±1 | |
| ⑤ 반올림 & 예외 처리 | 23비트 초과 부분 반올림, Overflow/Underflow 확인 |
10진수 floating point 예시

2진수 floating point 예시

division도 multiplication과 비슷하게 부호(sign), 지수(exponent), 가수(significand)를 나눠서 계산한다.
단계 이름 핵심 내용
| ① 부호 결정 (Sign) | (S = S_1 ⊕ S_2) (XOR) | |
| ② 지수 계산 (Exponent) | (E = (E_1 - E_2) + Bias) | |
| ③ 가수 나눗셈 (Mantissa) | ((1 + F_1) ÷ (1 + F_2)) 수행 | |
| ④ 정규화 (Normalization) | 결과를 1.x 형태로 맞추고 지수 ±1 조정 | |
| ⑤ 반올림 및 예외 처리 | 23비트만 유지, Overflow/Underflow/NaN 확인 |
FP Instructions in LEGv8
레지스터
- 32개의 단정밀도 레지스터: S0 ~ S31
- 32개의 배정밀도 레지스터: D0 ~ D31
- Sn은 Dn의 하위 32비트를 사용
- FP 연산은 FP 레지스터끼리만 가능 (정수 연산과 혼용 불가)
연산 명령어
| 단정밀도 (Single) | FADDS, FSUBS, FMULS, FDIVS | 32비트 float 연산 |
| 배정밀도 (Double) | FADDD, FSUBD, FMULD, FDIVD | 64비트 double 연산 |
| 비교 연산 | FCMPS, FCMPD | FP 비교 및 조건 코드 설정 |
| 분기 | B.cond | 비교 결과에 따라 분기 |
| 로드/스토어 | LDURS, LDURD, STURS, STURD | FP 레지스터 ↔ 메모리 |
예시:
FADDS S2, S4, S6 // S2 = S4 + S6
FADDD D2, D4, D6 // D2 = D4 + D6예시 — °F → °C 변환
C 코드:
float f2c(float fahr) {
return ((5.0/9.0) * (fahr - 32.0));
}LEGv8 어셈블리
f2c:
LDURS S16, [X27,const5] // S16 = 5.0
LDURS S18, [X27,const9] // S18 = 9.0
FDIVS S16, S16, S18 // S16 = 5.0 / 9.0
LDURS S18, [X27,const32] // S18 = 32.0
FSUBS S18, S12, S18 // S18 = fahr - 32.0
FMULS S0, S16, S18 // S0 = (5/9) * (fahr - 32.0)
BR LR // return💡 X27은 정수 레지스터로 메모리 주소를 가리킴,
S16, S18, S0은 FP 레지스터로 실수 계산 수행.
