
개념
1. Ensemble Learning 정의
- 앙상블 학습: 여러 개의 모델(Base Learners)의 결과를 결합하여 정확한 예측을 수행하는 기법.
- 목표: 단일 모델보다 더 좋은 성능을 얻는 것.
- 적용 범위: 지도학습(Supervised Learning) 에만 적용 가능 (예: 분류, 회귀)
- 비지도학습(예: 군집화)에는 사용 불가
2. 기본 용어
- Base Learner (기초 학습기): 단독으로도 사용 가능한 기본 모델 (예: 의사결정트리, KNN 등)
- Ensemble Learner (앙상블 모델): 여러 base learner들의 출력을 조합해 만든 모델
3. Ensemble Learning 작동 원리
- 여러 데이터셋 생성 (D₁, D₂, ..., Dₜ)
- 여러 base classifier 학습 (C₁, C₂, ..., Cₜ)
- 결과 결합하여 최종 예측 C*

4. Ensemble Learning이 효과적인 이유
앙상블의 성능은 각 모델의 독립성과 다양성에 달려있다.
정확(accurate)하면서도 다양한(Diverse) 모델이 서로 다른 종류의 오류를 범하면 서로의 오류를 상쇄함으로써 정답률을 높이는 방식이다.
base classifier가 총 25개이고 각 classifier의 오차율이 0.35이며 서로 독립이라 가정하자
앙상블은 다수결로 최종 예측을 하기 때문에 13개 이상이 틀릴 경우 틀렸다고 할 수 있다. 전체 25개중 13개가 오답일 확률은 0.06으로 줄어들게 된다.

5. Ensemble 구성 전략

6. Ensemble 기법 분류
Ensemble learning은 크게 Aggregation Methods와 Ensemble Methods 두 가지로 나눌 수 있다.
Aggregation 방식은 미리 학습된 여러 모델(Base Learners)의 예측값을 조합하여 최종 예측을 도출하는 방법이다.
base model들은 이미 독립적으로 학습을 마친 상태이며 새로운 데이터가 들어오면 단순히 predict만 수행한다.
(voting, stacking)
Ensemble 방식은 단순히 예측값을 조합하는 것에 그치지 않고, base model을 다양하게 생성하고 학습 데이터를 바꾸며, 반복적인 학습 구조를 통해 모델을 만들어낸다.
(Bagging, Boosting, Cascading)
모든 앙상블 기법은 예측 시점에 predict만 수행한다. voting/stacking은 미리 지정된 모델을 조합하는 구조이며, Bagging/Boosting은 모델을 반복 생성하고 학습하면서 구조적으로 성능을 향상시킨다.

Aggregation Methods
✅ Voting
- 여러 개의 base model이 독립적으로 예측을 수행한 뒤,
그 결과를 다수결(Hard Voting)이나 확률 평균(Soft Voting) 방식으로 결합한다. - 예측 시점에는 각 모델은 학습이 끝난 상태이며, 단순히 예측만 수행한다.
- 모델 수는 개발자가 직접 고정하여 지정
✔ 예: SVM, Tree, KNN 3개로 구성 → 항상 이 3개 모델만 사용
✔ 학습은 각 모델별로 fit() 한 번씩만 수행
✔ 예측은 각 모델에서 predict() → Voting 함수에서 조합
model1 = DecisionTreeClassifier().fit(X_train, y_train)
model2 = KNeighborsClassifier().fit(X_train, y_train)
model3 = SVC(probability=True).fit(X_train, y_train)
# 이제 3개 모델의 예측을 투표로 조합
pred1 = model1.predict(X_test)
pred2 = model2.predict(X_test)
pred3 = model3.predict(X_test)
final_pred = majority_vote([pred1, pred2, pred3])
✅ Stacking
- 여러 base model을 먼저 학습한 뒤,
이들이 생성한 예측값(pred₁, pred₂, ...) 을 새로운 입력 feature 로 사용한다. - 이 feature를 입력으로 받아 meta-model(결합기) 을 학습시켜 최종 예측을 수행
- 예측 시에는:
- base model들이 예측 수행 → [pred₁, pred₂, ...] 생성
- 이걸 meta-model에 입력 → 최종 predict() 수행
- 여기서도 모든 모델은 사전 학습(fit) 을 마친 상태이며, 예측 시에는 단지 predict()만 수행
✔ base model과 meta model 모두 fit() → 그 이후 예측만 함
✔ 예측 구조: tree.predict(), svm.predict() → meta_model.predict()
# base model
tree = DecisionTreeClassifier().fit(X_base, y_base)
svm = SVC(probability=True).fit(X_base, y_base)
# base model의 예측값 수집
# 학습을 위한 예측값이므로 학습 과정이라고 봐야함
z1 = tree.predict_proba(X_meta)
z2 = svm.predict_proba(X_meta)
# meta feature: base model 예측값
Z = np.column_stack([z1[:,1], z2[:,1]])
# meta model 학습
meta_model = LogisticRegression().fit(Z, y_meta)
Ensemble Methods
✅ Bagging
- 학습 데이터를 중복 허용(Bootstrap) 방식으로 샘플링하여 여러 개의 데이터셋 생성
- 각 base model은 서로 다른 데이터로 학습되고, 결과는 평균(회귀) 또는 다수결(분류)로 조합하여 분산을 줄일 수 있다.
- 모델 수는 보통 n_estimators로 지정하지만, 예측 시에는 학습된 모든 모델이 예측을 수행하고, 조합한다.
✔ 각 모델은 학습 시 개별적으로 만들어지고 학습됨
✔ 예측 시 새로운 입력에 대해 모든 모델이 predict() → 결과 평균 또는 다수결
예제)
1차원 x값에 대해 1과 -1의 이진 분류를 실행하는 decision stump가 있다고 하자


bootstrap 방식으로 10개의 데이터셋을 샘플링 한 후 각각 다른 base model로 학습해보자
이 예제에서는 base model이 Decision stump 하나만을 써서 parameter를 조정해 다른 base model을 생성했다.
bootstrap으로 뽑은 데이터를 기준으로 가능한 모든 분기점(candidate split)을 시도하면서 분류 오류가 가장 적은 지점을 선택하는 방식으로 decision stump를 학습시킨다.


학습 결과

예측 과정

각 모델들이 학습한 결과를 바탕으로 예측을 수행하고 예측값들에 대한 다수결(분류) 혹은 평균(회귀)를 계산한다.
새로운 데이터가 들어올때마다 model들은 predict를 수행하고 그 예측값들에 대해 새로 계산하는 방식이다.
✅ Random Forest
- Bagging의 확장 버전으로, 각 모델(결정트리)이 데이터뿐 아니라 사용하는 feature도 무작위로 선택
- 이는 base model 간 다양성을 더욱 증가시켜 과적합을 줄이는 효과를 준다.
✔ 예측 과정은 Bagging과 동일
✔ 각 트리는 서로 다른 feature subset으로 학습됨
주요 하이퍼 파라미터

✅ Boosting (AdaBoost, GB, XGBoost)
- base model들을 순차적으로 학습시키며, 이전 모델이 틀린 샘플에 더 집중한다.
- 점점 더 어려운 샘플에 잘 대응하도록 모델을 보정해나가는 방식
- 각 모델의 예측 결과를 가중합하여 최종 예측을 수행
- 보통 n_estimators로 모델 수를 설정하지만, 성능 향상이 멈추면 early stopping이 발생하기도 한다.
✔ 예측은 학습된 모든 base model이 순차적으로 predict()
✔ 결과를 누적 또는 가중합하여 최종 예측을 생성
AdaBoost
예측에 실패한 데이터에 집중할 수 있게 샘플 가중치를 조정하는 방식을 사용한다.
- 먼저 초기 데이터셋 D1에 모든 샘플 가중치를 동일하게 설정한다.
- 약한 분류기 C1을 학습한다.
- 가중치 𝛼1을 계산한다.
가중치를 계산하는 방식
먼저 전체 오차율을 계산한다.
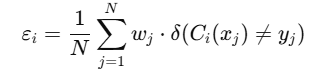

예측이 틀렸으면 Indicator 함수 부분이 1이되어 가중치가 포함되고 맞으면 0이되어 가중치를 무시하여 예측에 실패한 데이터에 집중할 수 있게한다.
그 후 분류기를 얼마나 신뢰할 수 있는지를 나타내는 중요도 α 를 계산한다. α 는 나중에 다수결할 때 가중치로 사용된다.

4. 샘플의 가중치를 업데이트 한다.

마찬가지로 예측이 맞았으면 가중치를 줄이고 틀렸으면 가중치를 증가한다.
5. 가중치를 기반으로 새로운 데이터셋 D2를 생성한다.
이때 새로운 가중치를 기반으로 복원추출을 하는 확률적 복원추출을 사용한다. 쉽게말해 확률이 있는 bootstrap 방식으로 이해하면 된다.
6. 정해진 반복횟수를 채웠거나 에러율이 50%이상일 경우까지 2-5번을 반복한다.
최종 예측


여기서 y는 가능한 모든 클래스 후보를 의미한다.
AdaBoost의 최종 예측은 마지막 모델이 아니라 전체 모델의 합의 결과이다.
각 모델의 중요도 α 를 반영한 가중 다수결 투표로 이루어진다.
x에 대한 분류기의 예측 결과가 다음과 같을 때

A의 합은 0.3+0.2=0.5 이고 B의 합은 0.4+1.0=1.4로 y의 값중 가장 합이 큰 B가 최종예측 결과가 된다.
예제)

샘플을 뽑아보자

decision stump가 0.75를 기준이 되도록 학습이 되었다. 그런데 0.1,0.2,0.3의 값은 예측이 실패했으므로 3개에 대해 가중치를 계산하여 증가하고, 나머지는 가중치를 감소시킨다.
그리고 변경된 가중치로 샘플을 뽑았는데 이번엔 0.05가 기준이 되었다고 가정해보자

그러면 0.4,5,6,7 의 4개 값이 예측이 틀렸고 이 4개에 대한 가중치를 증가시키고 나머지는 감소시킨다.
아래 예시는 이해하기 쉽도록 극단적으로 가중치를 변경한 값이다.

최종 예측을 할 때는 클래스별로 알파값(가중치)를 더해서 가중치가 큰 클래스를 택한다.

Gradient Boosting
1. 핵심 개념
- 여러 개의 **약한 예측기(보통 작은 Decision Tree)**를 순차적으로 쌓아가며,
이전 모델의 오차(잔차)를 예측하여 보완하는 방식.
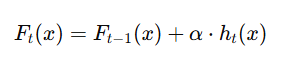

알파 값은 learning rate , 기본 값은 0.1이다. 0.1 보다 작아지면 일반화는 잘 되지만 더많은 트리가 필요하고 시간이 오래 걸린다. 반대로 값이 클 경우는 빠르게 수렴하지만 과적합 위험이 있다. cross-validation이나 GridSearchCV등으로 최적값을 탐색하자
2. 학습 알고리즘 흐름


날씨와 골프를 치러 오는 사람의 수의 관계를 나타낸 데이터셋이 있다.
타겟이 연속적인 값이므로 회귀 트리를 학습시키는 방식과 동일하게 만들어진다.
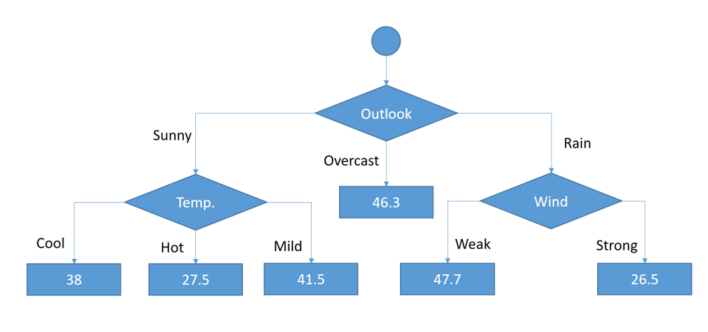
MSE가 줄어드는 방향으로 트리를 생성하고 각 left 노드에 해당하는 타겟의 평균을 구한다.
그 다음, 각 데이터 샘플에 대해 에러를 계산한다. 예시로 1번째 데이터는 sunny-hot이므로 27.5 여야하지만 실제는 25이므로 error = -2.5가 된다. 그런식으로 에러를 모두 구한 후 데이터셋을 업데이트 한다.

이 이후는 오차(residual)에 대해 decision tree를 생성한다.
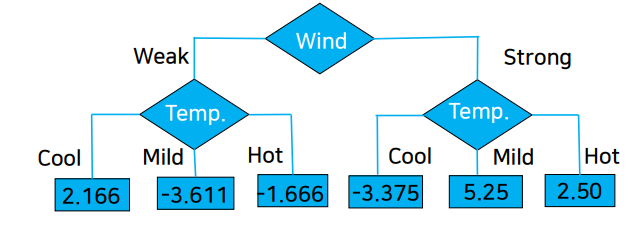
마찬가지로 오차를 업데이트 하면

이런 식으로 5번 반복을 해보면

예측값과 실제값이 꽤 비슷해진다. 예제에서는 편의를 위해 알파값을 1로 뒀지만 일반적으로는 0.1을 쓴다.
XG Boosting
기존의 Gradient Boosting을 속도, 성능, 정규화, 병렬 처리 측면에서 대폭 향상시킨 알고리즘이다.
구체적은 내용은 다음에....
✅ Cascading
- 여러 모델을 단계적으로 연결해,
앞 단계에서 자신 있는 예측은 유지, 자신 없는 예측은 다음 단계의 모델에 넘긴다. - 신뢰도가 낮은 경우만 복잡한 모델을 실행함으로써 계산 효율성을 높이는 방식
✔ 예측은 조건에 따라 모델을 선택해가며 진행
✔ 학습은 각 단계별 모델마다 독립적으로 수행됨
